
BlueGreen Labs follows the current developments in Large Language Models (LLM, e.g. ChatGPT) closely, as AI and LLM in particular have profound effects on how science is and will be conducted. We consider it important to acknowledge the potential of this technology but we also see vast opportunities for misuse within science, and especially academia. We will briefly outline some of opportunities and dangers we see in these rapidly developing technologies within science and academia - and justify our final position.
Writing, reporting & research
The singular strength of LLM is to create plausible sounding texts based upon user prompts. These models therefore have been described as stochastic parrots, linking highly likely word combinations into a somewhat coherent text (Bender et al. 2023). Although the truth is slightly more complicated, it remains so that LLM (as of writing) perform badly in linking (learned) text context with other parts of reality, for example a real body of scientific literature. It must be repeated that LLM are not search engines, although often used in such a way. Recent implementations of LLM with web search ability blurs the lines here, and agent based crawlers or services can alleviate some of these issues.
Pro:
- Generation of ideas
- Battles writers block
Con:
- Specious
- Reinforcing biases
- Fake attribution
- Not a search engine
Code & data management
Impacts of LLM on code development and therefore project management as a whole can be considered positive. Menial tasks such as data cleaning can be accelerated, due to the flexibility of these models to deal with idiosyncratic input (and continuous incremental corrections). However, most LLM are run on remote hardware.
When dealing with sensitive data the use of such services, as with any un-encrypted cloud service, can be troublesome. Sensitive information should be kept of off such services, as there has been (as of writing) demonstrated some evidence of cross- (chat-) session data leaks. These services, given their dynamic learning capacities and opaque governance need to be explicitly considered with the context of Internal Review Board (IRB) assessments.
In the hands of already experienced coders LLM can be a powerful aid. In the hands of less experienced coders the tendency of these models to hallucinate, by producing plausible results, could lead to the proliferation of poor implementations at a large scale. In short, LLM can speed up the generation of code solutions for those who know what they are designing and or aiming for. Those with less skill can be lead astray, by the lack of their own direction, or blindly following LLM suggestions.
Pro:
- Easy data cleaning of idiosyncratic data formats
- Easy code review
- Speed up documentation
- Pair coding using LLM
Con:
- Data privacy issues
- Poor code at scale
- Code with poor scope and direction
Scientific & academic impact
The current metric driven science culture, and its moral hazards, as it stands leads to fraud and misconduct. ChatGPT and LLM has the potential to accelerate science even further, creating larger potential for moral hazard (fraud) and an effective race to the bottom. Volumes of LLM created “science” might vastly outstrip the demand of human review.
The current implementation of LLM are also pay as you go services, concentrated in the hands of a few quasi-monopolies. This business model strongly favours entrenched power dynamics, and those with the most resources. The application of LLM is therefore at odds with a merit based system, and mostly favours the wealthy.
Educators will have to battle the authoritative, but wrong, answers provided by Chat bots in homework and written essays. Additional scrutiny will be required by educators in assessments, and further burdened in explaining the weaknesses in resource verification of these LLMs.
Conclusion
Within BlueGreen Labs we are not averse of these technological advancements. However, we strongly question who benefits from this technology, how does this impact scientific practices, the community standards, and exiting power structures.
As of writing, we estimate the overall impact of LLM on scientific practices to be a net negative. It entrenches research practices where we should be moving away from them (Urai and Kelly 2023, Figure 1). Those with the means, and the knowledge, will be able to move very fast with the same or increased accuracy.
In contrast, it will tempt those who need to “move” results quickly, in the metric driven rat-race, into sloppy scientific practices (form homework to journal alike). Not only will it increase review loads, and decrease the signal to noise ratio of trustworthy research, it also kicks in the door to plagiarism, and outright fraud.
Unlike what has been argued, we do not consider the implementation of LLMs as a democratizing force in science and rather will move it away from a holistic and growth agnostic endeavour, supercharging the current rat race and favour those who get savvy with (LLM) systems.
Within this context, BlueGreen Labs will refrain from using LLMs within the context of our final written work, and deploy it conscientiously throughout the scholastic process (if at all). We might revise our stance depending on the development of this technology.
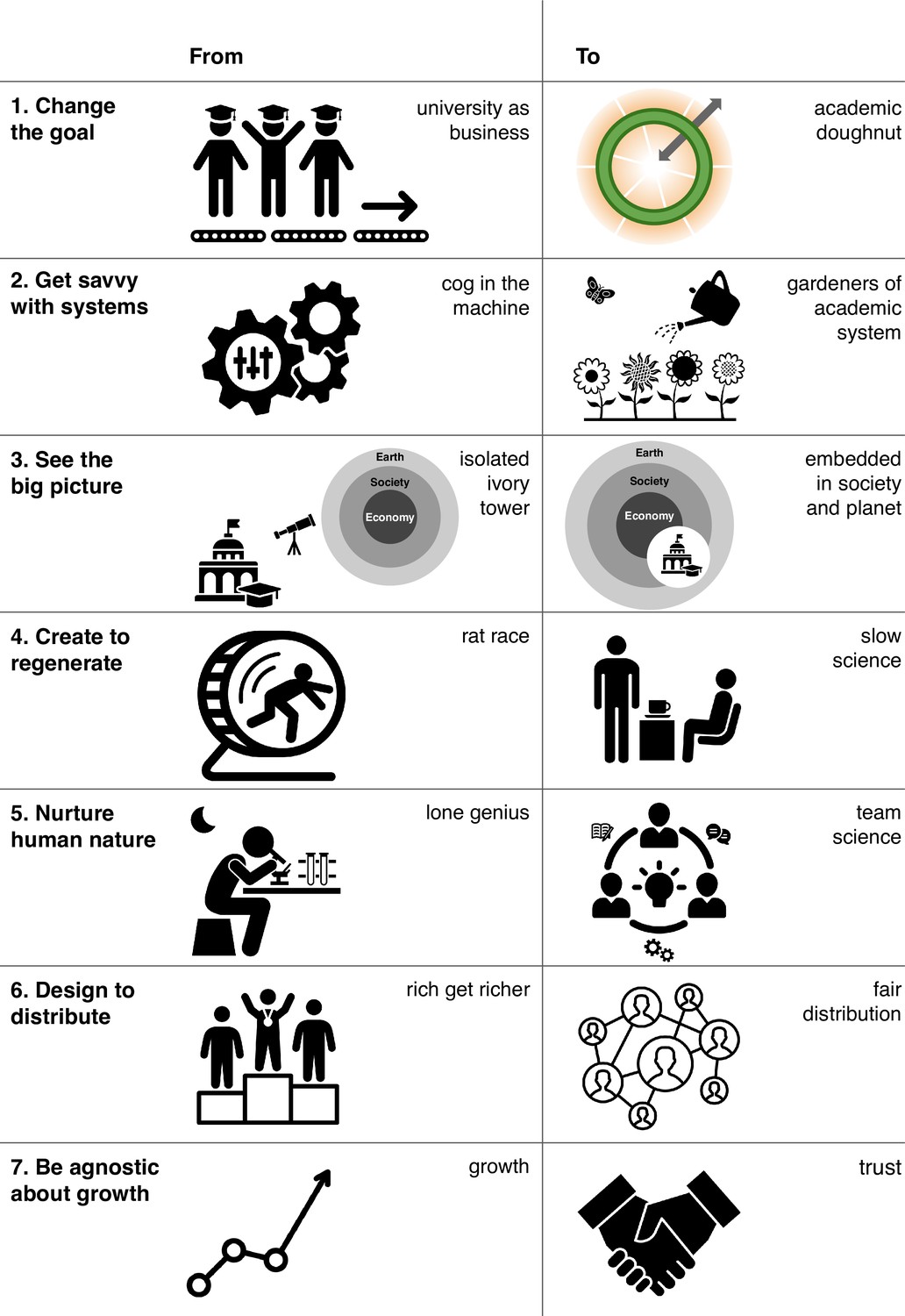
Figure 1: From Urai & Kelly eLife 2023
References
Bender et al. 2023 - On the Dangers of Stochastic Parrots: Can Language Models be Too Big? - ACM (https://doi.org/10.1145/3442188.3445922)
Urai and Kelly 2023 - Point of View: Rethinking academia in a time of climate crisis - eLife (https://doi.org/10.7554/eLife.84991)